1/2 Day
Practicing Agile Data Science is an interactive course for data science and analytics teams that covers the methods for applying agile strategies outlined in the book Agile Data Science 2.0. It teaches agile data science team members, including product/project managers, data scientists, software engineers and designers how to set up, structure and manage analytics projects. We’ll go over the history of the waterfall method and the emergence of agile methods. We'll cover agile software engineering. We'll give an introduction to Big Data and what it means beyond the hype. We'll show the differences between software engineering and data science that require changes to make agile methods effective.
The course trains students to adapt to the dynamic nature of data science, which is both engineering and science. It puts the focus of the team on creating an application for their problem domain that describes their datasets and guides them on their critical path to unlock value. This application serves to enable customer interaction, the bedrock of agile methods. This interaction helps to avoid common pitfalls in agile data science and can deliver consistent, predictable results.
Three Days, 8 Hours Per Day = 24 Hours
6 students
This is a professional development class that teaches how to iteratively craft entire analytics web applications using Python, Flask, Spark (SQL, Streaming, MLlib), Kafka, MongoDB, ElasticSearch, Bootstrap and D3.js. This stack is a popular one and is an example of the kind of stack needed to process and refine data at scale in real world applications of data science. During this course, students will use airline flight data to produce an entire analytic web application, from the ground up.
The course will serve as a tutorial in which the student learns basic skills in all the categories needed to ship an entire analytics application. Each section, the student will add a layer to their application, creating the start of something they can really use in their respective domains. While users will not learn the tools in detail, they will establish the working foundation needed, and will practice the kind of active learning-as-you-go that analytics requires. The goal of the course is to establish a working foundation with working code that the student can extend as they learn going forward. Working end-to-end code makes learning much easier.
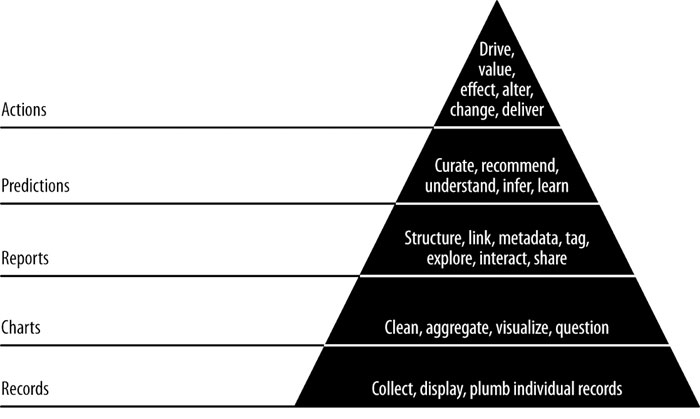
The organizational principle behind the course is the 'data value pyramid', pictured below. Students will climb the data-value pyramid, refining data at one step to reach the next.
This class will be a chance for a practicing data scientist or web developer to learn to turn their data and analyses into full-blown actionable web applications. We will put the student in a position where she can independently improve on the foundation we have given her to go on to build great analytics applications
The course appeals to one of the following persons:
Programmers who want to learn introductory data science.
Practicing statisticians who want to learn to build entire applications.
Entry level data scientists who want to learn how to craft full-stack applications
The difficulty of the material is intermediate. While all the content we cover is introductory, the breadth of the material we cover makes this an intermediate challenge.
The course can be tailored to meet the needs of data science teams. Teams will learn to work together to create full-stack applications. Each student will learn their individual role, as well as how to collaborate using agile development to do data science.
Students should be fluent programmers in at least one language, preferably Python and with some experience in Javascript. Exposure to data analysis on some level is required, but that might be limited to SQL. We can provide a pre-test which students should pass to benefit optimally from the course.
A virtual machine image for use with either Vagrant or Amazon EC2 will be provided which will contain the environment for the course. Data for the course will be downloadable. Students wishing to install the tools on their own computers can refer to Appendeix A of Agile Data Science 2.0 (O'Reilly, 2017), which contains detailed installation instructions. We won't cover a custom install in the course directly.
Students will learn the theory and practice of employing agile development principles to build entire analytics applications. Students will gain real-world experience building all aspects of a real analytics application.
A lecture on theory will begin the course, followed by a lecture and examples illustrating how the tools form a complete data platform. Next a lecture explaining the dataset used in the course. After this, the remainder of the course will be guided exercises.
We will iteratively extract increasing amounts of value from raw data as we refine it in stages that correspond to the levels of the data-value pyramid.
Exercises throughout the course will ensure that students learn to apply what they are learning. Students will end up with a simple web application and data processing scripts they can alter and customize to fit their own problem domain and their own dataset.
By the end of this course...
Participants will understand:
Participants will be able to:
What are 2-3 of the most common ideas, skills, or performance abilities that someone new to this content struggles with?
Throughout the course, students will work with source code on a virtual machine/Amazon EC2 image and in github which they can run, tweak and modify to learn. In addition, some portions of the course will include Jupyter or Zeppelin notebooks. There will be an assessment in each section, where the student takes what they've learned and extends an example to do something new.